

معرفی پردازش زبان طبیعی(NLP) شاخهای از هوش مصنوعی
آیا تابه حال به این فکر کردهاید موتورهای جستجوی گوگل چطور زبان انسان را متوجه میشوند؟ حتی اگر در قسمت جستجو متن را اشتباه تایپ کنید بازهم متوجه منظور شما میشوند؟ فناوری وجود دارد که به آن پردازش زبان طبیعی میگویند.
این تکنولوژی پیچیده یکی از شاخههای هوش مصنوعی است که به ماشین اجازه میدهد، زبان طبیعی انسان را تفسیر، پردازش و درک کند.
در ادامه این مقاله مدل هوش مصنوعی NLP را به طور کامل معرفی میکنم و تاثیر آن را در موتورهای جستجوی گوگل و بهبود سئو توضیح میدهم. اگر میخواهید در این زمینه فعالیت کنید یا اطلاعات خود را بروز کنید تا انتهای مطلب با من همراه باشید.
پردازش زبان طبیعی (NLP) چیست؟
پردازش زبان طبیعی یا Natural Language Processing که به اختصار به آن NLP گفته میشود. همانطور که گفتم شاخهای از هوش مصنوعی است که برای تفسیر، تحلیل، درک و تولید زبان انسانی توسط سیستمها استفاده میشود.
تحلیل زبان طبیعی انسان یا NLP همان فناوریای است که باعث میشود گوگل حتی با وجود اشتباه تایپی، منظور شما را بفهمد. در این مقاله علاوه بر معرفی کامل NLP، یاد میگیرید چطور از آن برای بهبود سئو و رتبه سایت خود استفاده کنید.
هدف این تکنولوژی به طور ویژه این است که ماشینها بتوانند زبان انسان را مانند ما بفهمند و بتوانند با آن تعامل برقرار کنند.
فرض کنید شما سوالی از گوگل یا ابزارهای مختلف AI میپرسید، اما متنی که مینویسید اشتباه تایپی دارد یا جمله بندی آن مشکل دارد. اما پاسخی که دریافت میکنید دقیقا مطابق چیزی است که شما نیاز داشتید.
سیستمهای پردازش زبان طبیعی جوری طراحی شدهاند که زبان انسانی را به شکل قابل فهمی برای کامیپوترها تبدیل کند.
NLP دوتا زیر مجموعه به نامهای NLU و NLG دارد.
- NLU یعنی (Natural Language Understanding) که به ماشین کمک میکند زبان انسان را با استفاده از استخراج متن از دادههای بزرگ، تحلیل و درک کند. این دادهها شامل کلمات کلیدی، احساسات، ارتباطات و انتقال مفاهیم میشوند.
- NLG یعنی (Natural Language Generation) برای استخراج بینشهای معنادار که به صورت عبارات و جملات در قالب زبان طبیعی هستند کاربرد دارد.
تاریخچه تحلیل زبان طبیعی
ریشه تحلیل زبان طبیعی به سال ۱۹۵۰ میلادی برمیگردد. آلن تورینگ در این بازه از زمان مقالهای با عنوان ماشینهای محاسباتی وهوش منتشر کرد که داخل آن آزمونی به نام آزمون تورینگ معرفی شد. این آزمون شامل وظیفهای است که در آن از تفسیر و تولید خودکار زبان طبیعی استفاده میشود.
از دهه ۱۹۸۰ به بعد مدلهای آماری و یادگیری ماشین جایگزین روش دستی شدند و دقت سیستمها افزایش یافت.
اما از سال ۲۰۱۰ به بعد تغییر شگرفی در این تکنولوژی رخ داد که با شبکههای عصبی عمیق و بعد از آن مدلهای ترنسفورمر مانند BERT و GPT ترکیب شد. امروز این تکنولوژی به وسیله مدلهای زبان بزرگ (LLM) به بالاترین سطح خود رسیده که قادر است زبان انسان را به صورت پیشرفته درک و تحلیل کند.
البته که این فناوری همچنان درحال پیشرفت است و روز به روز آپدیتهای جدیدی ارائه میشود.
اما بنظر شما این فناوری چرا مهم است؟
اهمیت پردازش زبان طبیعی در تعامل انسان و ماشین
مدلهای فهم زبان طبیعی اغلب برای انجام خودکار وظایف تکراری نیز کاربرد دارند.
وظایف تکراری شامل موارد زیر میشوند:
- خلاصهسازی محتوا
- ترجمه ماشینی
- طبقه بندی متن
- بررسی املا
همانطور که در بخش بالا توضیح دادم، NLP زبان طبیعی انسان را به زبانی قابل فهم برای ماشینها تبدیل میکنند.
اما این فناوری در بسیاری از زمینههای دیگر نیز اهمیت خیلی زیادی دارد.
مثلا در گذشته مردم باید خودشان را با کامپیوترها تطابق میدادند و با استفاده از کدنویسی برای کامپیوترها، نیاز خود را به دستگاههای مختلف انتقال میدادند.
اما امروزه هر فردی میتوانند با هر دستگاهی ارتباط برقرار کند بدون اینکه نیازی به آموزش داشته باشد.
به طورکل ماشین خودش را با انسان سازگار میکند.
درحال حاضر تمام سیستمهای هوشمند امروزی به NLP وابسته هستند.
برخی از سیستمهایی که پردازش زبان طبیعی پایهگذار آنهاست:
- چتباتها و دستگاههای هوشمند مانند Siri, Alexa و Google Assistant
- سیستمهای راهنمای مشتری
- موتورهای جستجو
- ترجمه ماشینی
- مدلهای زبانی مثل GPT
امروز بیش از ۸۰٪ دادههای جهان متنی هستند. بدون NLP، تحلیل این حجم عظیم غیرممکن است. همین فناوری است که باعث میشود موتورهای جستجو دقیقاً نیاز شما را بفهمند و بهترین نتیجه را نمایش دهند.
این باعث میشود که تعامل با ماشین طبیعی، انسانی و دقیقتر باشد. درکل یکی از پایههای هوش مصنوعی آینده همین پردازش زبان طبیعی است.
کاربرد NLP برای بهبود موتورهای جستجوی گوگل و سئو چیست؟
اکنون که با اهمیت این تکنولوژی پیچیده آشنا شدید بیایید کاربردهای آن را در موتورهای جستجوی گوگل و بهبود رتبه سئو بررسی کنیم.
مدلهای پردازش زبان کلمات، زمینه و روابط را آنالیز میکند تا به معنی آن برسد. در قسمت سئو تحلیل زبان طبیعی برای فهمیدن نیت واقعی کاربران کاربرد دارد. یعنی گوگل و دیگر موتورهای جستجو نتایج جستجو را دقیقا مطابق چیزی که مردم به دنبال آن هستند نمایش میدهند.
به جای اینکه روی کلمات کلیدی تمرکز داشته باشد، روی هدف کاربر یا سرچ اینتنت (Search Intent) تمرکز میکند.
مثلا اگر یک کاربر سرچ کند« چطور مدرک ICDL بگیرم؟» بدون تحلیل زبان طبیعی، گوگل متوجه منظور کاربر نمیشود و ممکن است کتابهای مروبطه یا مقالات دانشگاهی را نمایش دهد. اما با وجود NLP گوگل متوجه میشود که کاربر میخواهد بداند از چه روشی برای یادگیری این مهارت استفاده کند؟
براین اساس موتورهای جستجو سایتهای آموزش مجازی مانند مرکز آموزش هرمس را به کاربر نمایش میدهند.
بنابراین اگر سئوکار، نویسنده یا مقاله نویس هستید باید به این موضوع توجه کنید که نباید صفحات خود را صرفا با استفاده بیش از حد کلمات کلیدی پر کنید. موتورهای جستجوی گوگل به صفحاتی که براساس نیت واقعی کاربر سئو شده باشند رتبه بالا میدهد و سایتهایی که برخلاف این مسئله عمل کرده باشند افت رتبه میگیرند.
مسلما قبل از هرچیزی باید به سئو و تکنیکهای آن تسلط کافی داشته باشید تا بتوانید از فناوریهای موجود برای افزایش رتبه خود در صفحات گوگل استفاده کنید. برای یادگیری این مهارت تخصصی و درآمدزا پیشنهاد میکنم دوره آموزش جامع سئو در وب سایت هرمس را ثبت نام کنید و به کمک مجربترین اساتید، این مهارت را به صورت حرفهای آموزش ببینید.
الگوریتمهای گوگل مخصوص پردازش زبان
طبق پردازشهایی که NLP روی صفحات سایتهای مختلف در اینترنت انجام میدهد، گوگل برای فهم معنا از چند مدل استفاده میکنند. به این مدلها الگوریتم میگویند که در ادامه آنها را معرفی میکنم.
- الگوریتم RankBrain: بر روی فهم ارتباط بین جستجو و صفحات سایت کار میکند.
- الگوریتم BERT: زمینه را در هر کلمهای از جمله درک میکند. مثلا فرق بین «تو» و «برای» در جستجوها اینجا مشخص میشود.
- الگوریتم MUM: این الگوریتم به پرسشهای پیچیده پاسخ میدهد، تصاویر را تحلیل میکند و درک چندزبانه دارد.
اگر میخواهید اطلاعات بیشتری درمورد این الگوریتمها و دیگر الگوریتمهای رایج در گوگل کسب کنید، حتما مقاله منتشر شده در سایت هرمس را مطالعه کنید.
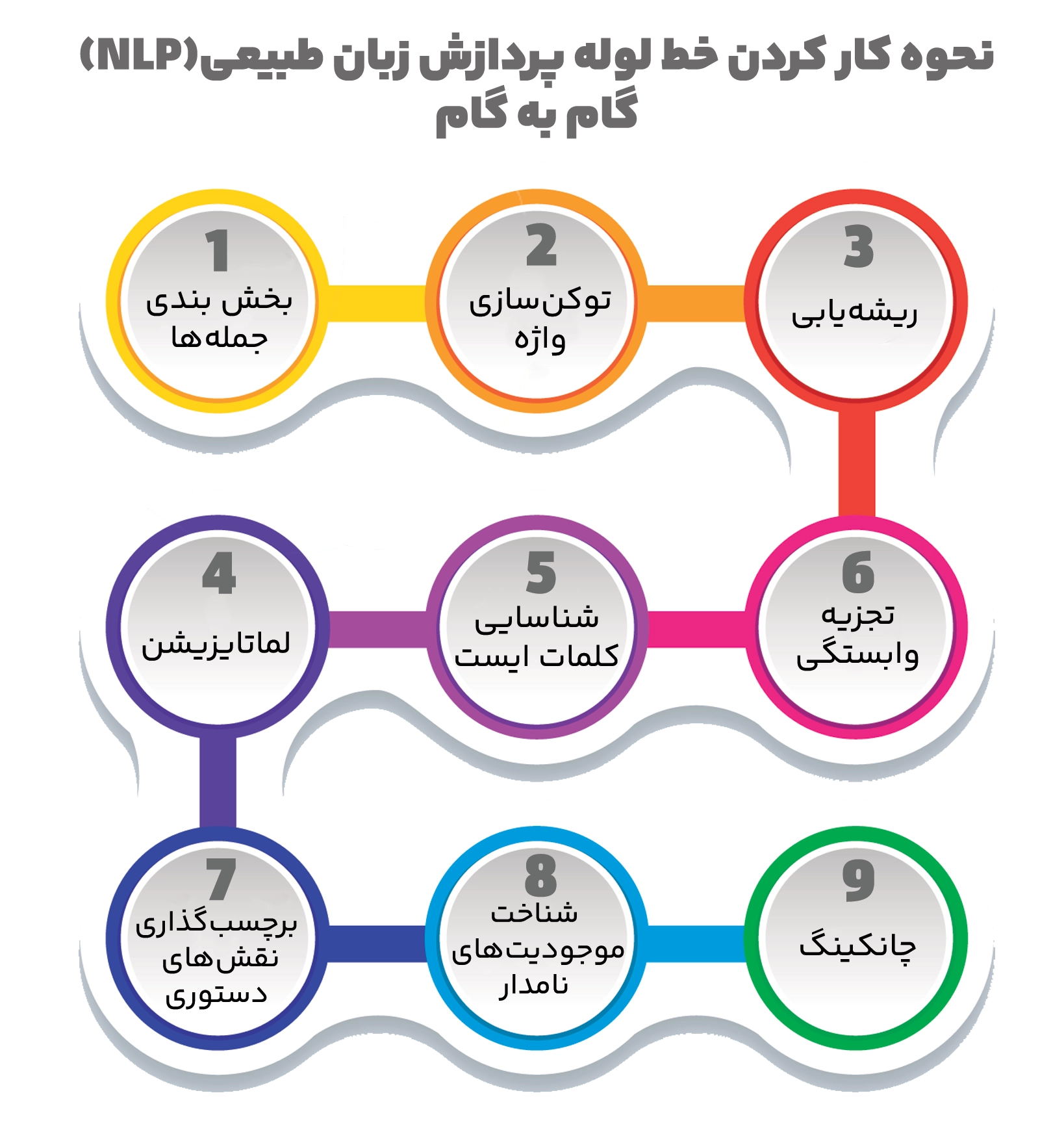
فناوری NLP چگونه کار میکند؟
پردازش زبان طبیعی چند مرحله دارد که به این مراحل خط لوله گفته میشود. در ادامه جزئیات معمول مراحل خط لوله NLP را بررسی میکنیم که چطور هر مرحله به پردازش و تحلیل دادههای متنی کمک میکند.

۱.بخش بندی جملهها (Sentence segmentation)
بخشبندی جملهها یکی از پایهایترین مراحل در پردازش زبان طبیعی (NLP) است. در این فرایند تلاش میکنیم متن پیوسته را به جملههایی مستقل تبدیل کنیم تا بتوانیم هر بخش را با دقت بیشتری مورد تحلیل زبانی قرار دهیم.
اجازه بدهید با شما صادق باشم؛ گرچه در ظاهر به نظر میرسد نشانههایی مانند نقطه، علامت سؤال یا تعجب برای تشخیص مرز جملهها کافی باشند، اما در عمل با چالشهای متنوعی روبهرو هستیم.
مواردی که میتوانند این مرزها را مبهم کنند:
- مخففها
- نقلقولها
- ایموجیها
- نشانهگذاری ناهماهنگ
اینجاست که اهمیت دقت در این مرحله خودش را نشان میدهد؛ چراکه تقریباً همه مراحل بعدی از توکنسازی تا برچسبگذاری کاملاً به درستی این جداسازی وابستهاند.
در زبان فارسی این حساسیت حتی کمی بیشتر است. وجود نیمفاصلهها، ساختهای محاورهای و تنوع نوشتاری باعث میشود ابزارهای تحلیل زبان انسان نیازمند دقت و ظرافت بیشتری باشند تا بتوانند واحدهای معنایی را بهدرستی تشخیص دهند.
اگر تجربهای در این زمینه دارید یا با چالشی خاص روبهرو شدهاید، خوشحال میشوم که در بخش کامنتها با من به اشتراک بگذارید.

۲.توکنسازی واژه (Word tokenization)
حالا اگر اجازه بدهید به موضوع مهم دیگری در حوزه پردازش زبان طبیعی بپردازیم : توکنسازی واژهها.
توکنسازی در واقع مرحلهای است که طی آن جمله را به اجزای کوچکتر از جمله:
- کلمات
- علائم نگارشی
- اعداد
- و حتی ایموجیها تقسیم میکنیم
تا مدلها و الگوریتمها بتوانند روی واحدهایی پایدار و قابل پردازش کار کنند.
البته این مرحله، مخصوصاً در زبان فارسی، پیچیدگیهای خاص خود را دارد. برای مثال، تفکیک درست پسوندها و پیشوندها، ضمایر متصل، نیمفاصلهها، و همچنین ترکیبهای واژگانی مانند «کتابفروشی» از چالشهای جدی در تحلیل زبان طبیعی به شمار میآیند. هرکدام از این عوامل میتوانند بر دقت مدلها اثر بگذارند و اگر بهدرستی مدیریت نشوند، تحلیل نهایی مختل خواهد شد.
نکته مهم دیگر انتخاب سبک توکنسازی است. بسته به نوع مدل یا وظیفهای که در پیش داریم، ممکن است رویکرد کاراکتری، روشهای زیرواژگانی مانند BPE ، یا توکنسازی واژگانی کلاسیک مناسبتر باشد. این انتخاب کاملاً تعیینکننده است؛ چون هم اندازه واژگان مدل و هم کیفیت فهم آن از متن را تحت تأثیر قرار میدهد.
در نهایت، کیفیت توکنسازی است که تا حد زیادی دقت ویژگیسازی و عملکرد مراحل بعدی مثل برچسبگذاری نقشهای دستوری را مشخص میکند.

۳.ریشهیابی (Stemming)
ریشهیابی روشی قاعدهمحور است که تلاش میکند شکلهای صرفی یک واژه را با حذف پیشوندها، پسوندها و نشانگرهای صرفی، به یک ریشهی تقریبی کاهش دهد. این رویکرد اگرچه دانش نحوی و معنایی ندارد، اما بهدلیل سادگی و سرعت بسیار بالا، همچنان در بسیاری از سامانههای متنمحور از جمله جستوجو، بازیابی اطلاعات و مدلهای کلاسیک ویژگیسازی کاربرد گستردهای دارد.
مزیت مهم ریشهیابی این است که اندازه واژگان را کاهش میدهد و به مدل کمک میکند شکلهای مختلف یک واژه را همارز در نظر بگیرد. با این حال، در زبان فارسی چالشهای جدی وجود دارد. تنوع صرفی افعال، ساختهای ترکیبی، ضمایر متصل و نیمفاصلهها گاهی باعث میشوند ریشهیاب بخشهایی از کلمه را نابهجا حذف کند یا تصویر دقیقی از معنای واژه ارائه ندهد.
به همین دلیل در NLP معمولاً ریشهیابی زمانی انتخاب میشود که این موارد برای ما مهمتر از ظرافت معنایی باشد.
- سرعت
- کارایی
- کاهش پیچیدگی واژگان
برای ما در مواردی که دقت معنایی و تحلیل ساخت واژه اولویت دارد، بهجای ریشهیابی معمولاً از lemmaسازی استفاده میشود که مبتنی بر تحلیل نحوی و معنایی است.
به طورکلی ریشهیابی کمک میکند شکلهای مختلف یک واژه معادل در نظر گرفته شوند.
مثلاً در موتور جستوجو:
«مینویسم»، «نوشت»، «نویسنده»، «نوشته»
همگی با ریشهیابی ممکن است به یک فرم ساده مثل «نويس» برسند، که برای جستوجوی گسترده مفید است.
در ادامه بیشتر درمورد لماسازی توضیح میدهم.
۴.لماتایزیشن (Lemmatization)
اکنون به مرحلهای رسیدیم که از نظر NLP نقشی کاملاً اساسی در فهم دقیق متن دارد. این مرحله لِماتایزیشن یا Lemmatization گفته میشود.
در لِماتایزیشن تلاش میکنیم واژه را نه صرفاً به یک ریشهی ساده، بلکه به صورت معتبر و ثبتشده در واژهنامه برگردانیم. تفاوت مهم این روش با ریشهیابی در این است که لِماتایزر برای تصمیمگیری به نقش دستوری، ساخت نحوی و سیاق جمله توجه میکند. بنابراین میتواند بین شکلهای مختلف یک فعل، جمعهای متفاوت اسمها، یا حتی کاربردهای معنایی پیچیده تمایز قائل شود و دقیقترین لِما را برگرداند.
نتیجه چیست؟
ما به مجموعهای از واژگان میرسیم که هم از نظر معنایی پاکترند و هم از نظر کاربردی قابلاتکاتر. به همین دلیل لِماتایزیشن در حوزههایی مانند:
- تحلیل معنایی عمیق
- سیستمهای پرسش و پاسخ
- خلاصهسازی
- مدلهای یادگیری نظارتشده
- و هر جایی که فهم واقعی زبان انسان اهمیت دارد، نقش ویژهای ایفا میکند.
البته این دقت بالا بهایی هم دارد. برای انجام لِماتایزیشن به منابع زبانی گسترده نیاز داریم:
- از جمله پیکرههای برچسبخورده، واژهنامههای دقیق، قواعد صرفی معتبر و گاهی حتی مدلهای آماری یا شبکههای عصبی.
- داخل زبان فارسی، به دلیل تنوع صرفی گسترده، افعال پیچیده و ساختهای ترکیبی، نیاز به این منابع دوچندان است.
مثلا در جملهٔ «دانشجویان رفتهاند تا پروژه را ارائه دهند»، لِماتایزر با توجه به نقش دستوری، صرف و معنای واژه تشخیص میدهد که «رفتهاند» شکل صرفشدهٔ «رفتن» است و لِمای صحیح را برمیگرداند؛ در حالیکه یک ریشهیاب ساده ممکن است خروجی نادقیقی مانند «رفت» یا «رو» تولید کند و ظرافت معنایی را از بین ببرد.

۵.شناسایی کلمات ایست (Identifying stop words)
تا حالا فکر کردهاید که وقتی در گوگل چیزی جستوجو میکنید، بعضی کلمات در متن واقعا اهمیتی ندارند و الگوریتمها روی کلمات مهمتر تمرکز میکنند؟
این دقیقا همان کاری است که در NLP با شناسایی کلمات ایست انجام میشود. در این مرحله، واژههایی که بسیار پرتکرار و کماطلاعاتاند مثل حروف اضافه، حروف ربط و ادات علامتگذاری یا حذف میشوند تا مدلها روی بخشهای محتواییتر متن تمرکز کنند.
مثلا در جملهٔ «دانشجو به دانشگاه از خانه رفت»، واژههای «به» و «از» اطلاعات زیادی درباره موضوع متن نمیدهند، پس در تحلیل جستوجو یا دستهبندی متن میتوان آنها را حذف کرد تا مدل بهتر متوجه شود «دانشجو» و «دانشگاه» کلمات کلیدی هستند.
البته فهرست کلمات ایست باید به زبان و زمینه کاری متن متناسب باشد. داخل فارسی معمولا واژههایی مثل «را»، «از»، «و» و «به» در این فهرست هستند، اما در برخی تحلیلها مثل بررسی سبک نوشتار یا دستور زبان حذف آنها اشتباه است. بنابراین، بهترین راهبرد این است که فهرست کلمات ایست پویا و قابل تنظیم بر اساس هدف و داده واقعی باشد.
۶.تجزیه وابستگی (Dependency parsing)
آیا تا به حال فکر کردهاید که وقتی جملهای را میخوانید، مغزتان چگونه متوجه میشود چه واژهای نقش فاعل دارد و چه واژهای مفعول است؟
این کار در فهم زبان طبیعی با تجزیه وابستگی انجام میشود. برای این مرحله مشخص میکنیم هر واژه به کدام واژه دیگر وابسته است و چه نقشی دارد مثلا فاعل، مفعول یا قید. این مدلسازی برای کارهایی مانند استخراج رابطهها، پاسخگویی به سؤال، خلاصهسازی متن و تحلیل ساختاری جملات بسیار مفید به شمار میرود.
برای مثال، در جمله «دانشجو گزارش را نوشت»، تجزیه وابستگی مشخص میکند که «دانشجو» فاعل و «گزارش» مفعول «نوشت» است. چنین ساختاری باعث میشود الگوریتم بتواند دقیقتر روابط معنایی را استخراج کند، حتی اگر جمله طولانی یا پیچیده باشد.
۷.برچسبگذاری نقشهای دستوری (POS tagging)
آیا تا به حال فکر کردهاید که چگونه کامپیوترها میفهمند یک واژه در جمله اسم ، فعل یا صفت است؟
طی این مرحله، به هر توکن یک برچسب اختصاص داده میشود. برای مثال اسم، فعل، صفت، قید یا حرف اضافه تا اطلاعات دستوری لازم برای مراحل بعدی فراهم شود. این لایه، در واقع ستون فقرات بسیاری از پردازشهاست؛ از جمله لِماتایزیشن و چانکینگ.

۸.شناخت موجودیتهای نامدار (Named entity recognition)
بنظرتان در یک متن خبری یا مقاله، چگونه سیستمها میتوانند نام افراد، مکانها یا سازمانها را از بقیه متن تشخیص دهند؟ این کار با تشخیص موجودیتهای نامدار (NER) انجام میشود.
NER واحدهای معنایی مهم در متن مانند شخص، سازمان، مکان، زمان و عدد را شناسایی و برچسبگذاری میکند. این فرآیند پل ارتباطی میان متن آزاد و داده ساختیافته است.
و برای کاربردهایی مانند موارد زیر بسیار حیاتی به حساب میآید.
- جستوجوی پیشرفته
- تحلیل خبر
- استخراج دانش
- سیستمهای پرسشوپاسخ
۹.چانکینگ (Chunking)
موتورهای جستجو چگونه میتوانند بخشهای مهم یک جمله را سریع پیدا کنند، بدون اینکه کل متن را تحلیل کنند؟
راهکاری برای این چالش وجود دارد که به آن چانکینگ میگویند.
چانکینگ توکنها (واژهها) را براساس نوع دستوری آنها مثل اسم، فعل یا حرف اضافه، گروهبندی میکند و آنها را به عبارتهای بزرگتر و معنیدار مثل عبارت اسمی یا فعلی تبدیل میکند. این کار بدون نیاز به تحلیل کامل جمله، کمک میکند بخشهای مهم متن سریعتر شناسایی شوند.
کاربرد این اطلاعات چیست؟
- پیدا کردن کلیدواژهها
- خلاصهسازی متن
- جستوجوی الگوها
زبان های کدنویسی رایج برای توسعه سیستمهای پردازش زبان طبیعی
حالا که با همه مراحلی که یک سیستم هوش مصنوعی برای پردازش زبان طبیعی باید انجام دهد آشنا شدید، بیایید ببینیم با چه زبانهای برنامه نویسی میتوان این فناوری پیچیده را توسعه داد.
زبانهای متعددی هستند که مخصوص توسعه این فناوری استفاده میشوند و هرکدام کاربرد خاصی دارند. برای اینکه مناسبترین زبان کدنویسی را انتخاب کنید، باید نیاز و هدف خود را مشخص کنید.
پایتون (Python):
پایتون یکی از محبوبترین زبانهایی است که در حال حاضر توسعهدهندگان زیادی از آن استفاده میکنند. بیشترین کاربرد پایتون در زمینه NLP و یادگیری عمیق است به همین دلیل محبوبیت بالایی دارد. با استفاده از کتابخانههای متعدد و قدرتمندی ، جامعه کاربری بزرگی دارد.
مزیت کار با python یادگیری آسان، فرصتهای شغلی زیاد و مستندات فراوان است. البته این زبان فقط برای این تکنولوژی به طور خاص کاربرد ندارد و در زمینههای دیگر نیز مشاهده میشود. درحال حاضر اگر قصد دارید در این حرفه کاری مشغول شوید، بهترین روش برای یادگیری آموزش از طریق دورههای مجازی است.
مرکز آموزش هرمس یکی از بهترین مراجع یادگیری مجازی است که میتوانید در هر زمان و هر شرایطی دوره موردنظر خود را مانند دوره جامع زبان برنامه نویسی پایتون را خریداری کرده و آموزش را شروع کنید.
جاوا (Java):
زبان جاوا اغلب برای پروژههای بزرگ و صنعتی که نیاز به پردازشهای با سرعت بالا دارند استفاده میشود.
مزیت استفاده از جاوا یکپارچهسازی آسان آن با برنامههای سازمانی و مناسب بودن آن با سیستمهای بزرگ است.
Java حتی کار را برای توسعهدهندگان راحت کرده و ابزارهای آماده برای پردازش متن را به صورت کامل در اختیار قرار داده.
سی پلاس پلاس (++C):
سیستمهایی که دادههای بزرگی دارند و میخواهند با سرعت بالا آنها را پردازش کنند از ++C استفاده میکنند.
سی پلاس پلاس برخی کتابخانههایی را برای الگوریتم پایه NLP و موتورهای جستجو در خود قرار داده که کار با آن را راحتتر کرده.
البته یادگیری این زبان نسبت به زبان پایتون کمی سختتر است و ممکن است زمان زیادی ببرد. اما نمیتوان از کاربردها و مزیتهای آن غافل شد.
همچنین تمامی زبانهایی که در اینجا معرفی شدند را میتوانید از قسمت دسته بندیهای زبان برنامه نویسی در سایت هرمس آموزش ببینید.
ارتباط مستقیم NLP، یادگیری ماشین و یادگیری عمیق
قطعا پردازش زبان طبیعی(NLP)، یادگیری ماشین(ML) و یادگیری عمیق (Deep Learning) سه حوزه مرتبط هستند. اما همچنان تفاوتهایی نیز دارند. همانطور که در این مقاله گفتمNLP یک حوزه کاربردی است که با هدف تحلیل و فهم زبان طبیعی انسان طراحی شده. با ورود یادگیری ماشین، این فناوری توانست از الگوریتمهای آماری و مدلهای پیشبینی برای بهبود دقت خود و انعطاف پذیری بیشتر بهرهمند شود.
همچنین یادگیری عمیق زیر شاخهای از یادگیری ماشین است که به کمک شبکههای عصبی چندلایه ، امکان یادگیری خودکار را برای ویژگیهای داخل متن فراهم میکند.
چنین روشی باعث شده که دقت مدلها بسیار افزایش داشته باشد.
بیشتر بخوانید: الگوریتمهای رایج یادگیری ماشین
آینده این تکنولوژی قدرتمند چگونه پیشبینی میشود؟
براساس تحقیقاتی که انجام شده، آینده تکنولوژی فهم زبان طبیعی انسان پیشبینی میشود در سالهای آینده به طور برجستهای به سمت کاربردهایی مانند مراقبت بهداشتی حرکت کند.
اما اگر نمیتوانیم به قطع بگوییم در آینده این اتفاق خواهد افتاد. به این دلیل که آینده فناوریها با کاربرد NLP کاملا غیرقابل پیشبینی است. به هرحال هرچه این تکنولوژی بیشتر پیشرفت کند، پیشرفت فناوری هم روز به روز بیشتر خواهد شد.
اگر به دنبال رتبه یک گوگل هستید،NLP تنها یک مفهوم علمی نیست؛ ابزاری استراتژیک برای سئو است. همین حالا مقالههای دیگر هرمس را مانند اهمیت سئو سایت چیست بخوانید یا در دورههای تخصصی ثبتنام کنید تا از رقبا جلوتر باشید.
دوره آموزش نوشتن مقاله سئو شده با هوش مصنوعی
دیدگاه و پرسش